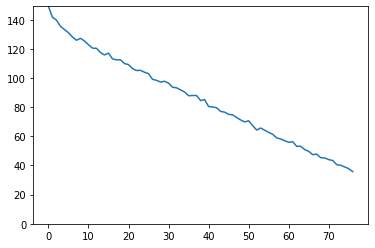
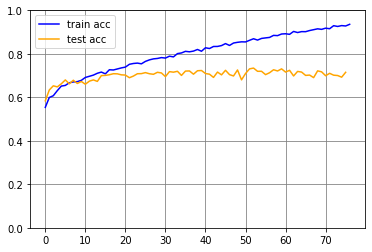
解いた問題はReal or Not? NLP with Disaster Tweets(https://www.kaggle.com/c/nlp-getting-started ) です。ツイート内容からを本物の災害かどうかを2値推定するというものです。精度を上げれば、どんな災害がいつどこで起きているかをツイッターの呟きから特定する、ソーシャルセンサーとして活用できる気もします。 先に結果を書いておくと、スコアは0.74539でした。
実装
モデルの概要図は下の通りです。
1 2 3 4 5 6 7 8 9 10 11 12 13
text ↓ embedding ↓ Positional Embedding ↓ Encoder Layers ↓ linear ← embedding ← keyword ↓ Sigmoid ↓ 出力
self.special_chars = [self.pad,self.oov_char,self.bos,self.eos] self.data = "" self._words=set() self.tokenize=disabletokenize self.tknzr = TweetTokenizer() defupdate(self,text): if(self.tokenize): self._words.update(text) else: self.data=self.tknzr.tokenize(text) #self.data=word_tokenize(text) self._words.update(self.data) self.w2i = {w: (i + len(self.special_chars)) for i, w inenumerate(self._words)}
self.i2w = {i: w for w, i in self.w2i.items()} self.w2i['<pad>'] = 0 self.i2w[0] = '<pad>' self.w2i['<unk>'] = 1 self.i2w[1] = '<unk>' self.w2i['<bos>'] = 2 self.i2w[2] = '<bos>' self.w2i['<eos>'] = 3 self.i2w[3] = '<eos>'
defencode(self,words): output=[] if(self.tokenize): pass else: #words=word_tokenize(words) words=self.tknzr.tokenize(words) for word in words: #辞書になし if word notin self.w2i: index = self.w2i[self.oov_char]#既存の<unk>を返す else: #辞書にあり index = self.w2i[word]#idを引っ張ってくる output.append(index) return output
defdecode(self,indexes):#使いどころないけど確認用 out=[] for index in indexes: out.append(self.i2w[index]) return out
trainデータを形態素に分解して単語を記録します。分解方法はNatural Language Toolkitのtweet tokenizerを使用しました。ハッシュタグやリプライ、顔文字も認識して分解してくれます。(最初は一般的な形態素解析ツールで分解していたため、これらが過度に分解されてしまい、文字が増えてしまいました)