Solving NLP classification problem "Contradictory, My Dear Watson"
Task To Classify
compettion link:https://www.kaggle.com/c/contradictory-my-dear-watson/overview
You can have multilingual premise and hypothesis pairs to train.They can be classifiaed into three relations; entailment,contradiction ,and neutral.The last category means that a pair is neither entailment nor contradiction.
A Task is detecting these relations from paired text using TPUs.
A Turtorial notebook is given here(https://www.kaggle.com/anasofiauzsoy/tutorial-notebook). I made some changes to it and finally it scored 0.70933. (Therefore, only additional code will be written below.)
Changing Turtorial Code
First of all, I run the tutorial code and the score was 0.64542.
It used a BERT model to pretrain and finetuned to answer.
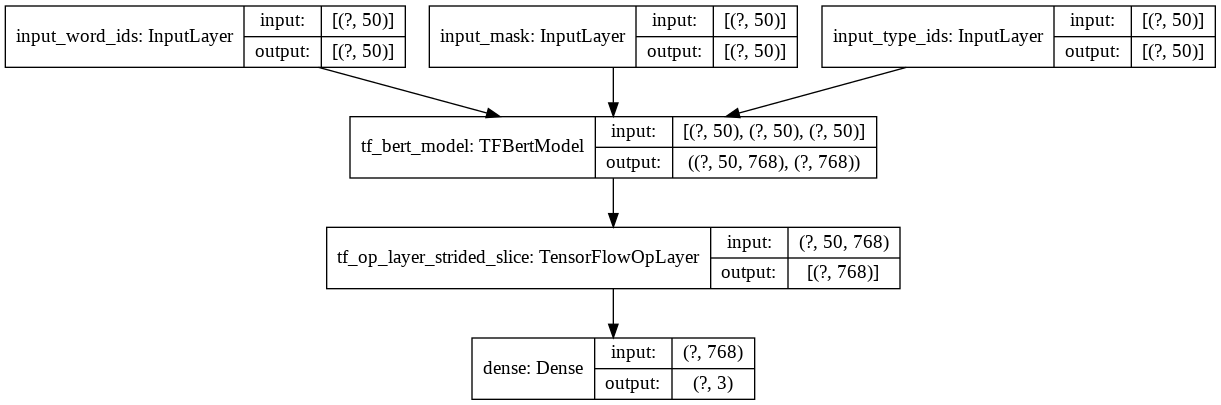
I changed two points for this model.
The first change is model type. I used XLM RoBERTa (jplu/tf-xlm-roberta-base) model and its pretrained parameters like this.
1 | from transformers import AutoTokenizer, TFXLMRobertaModel |
The Secondaly revision is translating all languages in English. I used googetrans libraly for this revision.
1 | !pip install googletrans |
The final Code is here (https://github.com/gojiteji/kaggle/blob/master/watson.ipynb).
I’ve trained in a single language because English accounts for about 60% in both train.csv and test.csv dataset this time. I think that the score will increase if I split it up into each language and let it learn the data because XLM RoBERTa is already scaled cross lingual sentence encoder.
references
kaggle “Contradictory, My Dear Watson” Turtrial notebook https://www.kaggle.com/anasofiauzsoy/tutorial-notebook
TPU Sherlocked: One-stop for 🤗 with TF https://www.kaggle.com/rohanrao/tpu-sherlocked-one-stop-for-with-tf
Hugging face Model: jplu/tf-xlm-roberta-base https://huggingface.co/jplu/tf-xlm-roberta-base