言語モデルの語彙の違いを見てみる
これはNAISTアドベントカレンダー2022 1日目の代理投稿です。
「語彙力がない」「ボキャ貧」なんて言葉を人間は使いますが,AIにもそういった特徴はあるのでしょうか?少し気になったので検証してみました.やり方は簡単で,言語モデルごとの語彙の集合を用いてベン図を描きました.
ソースコード:https://github.com/gojiteji/AI_vocab_comparison/blob/main/Vocab_comparison.ipynb
注意:
トークン化手法ごとにprefixが違う場合あります.異なるトークン化手法を用いているものは,prefixは全て削除しました.従って,後続トークンとしてのback(ex. feedback)と,先頭トークンとbackが同一トークンとして扱われます.また,extra idや言語コード,special tokenは削除しておりません.
T5 vs mT5
| モデル名 | トークン化手法 | データセット | リンク |
|---|---|---|---|
| T5 | SentencePiece | C4 | https://huggingface.co/t5-small |
| mT5 | SentencePiece | mC4 | https://huggingface.co/google/mt5-small |
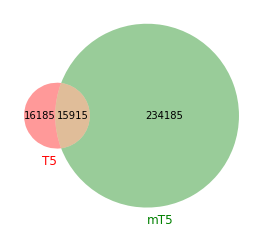
データセットがC4より多いmC4を使っているだけあって,mT5の方が語彙サイズがとても大きいことがわかります.
mBART25 vs mBART50 vs mT5
| モデル名 | トークン化手法 | データセット | リンク |
|---|---|---|---|
| mBART25 | SentencePiece | Common Crawl | https://huggingface.co/facebook/facebook/mbart-large-cc25 |
| mBART50 | SentencePiece | Same as mBART25 | https://huggingface.co/google/facebook/mbart-large-50 |
| mT5 | SentencePiece | mC4 | https://huggingface.co/google/mt5-small |
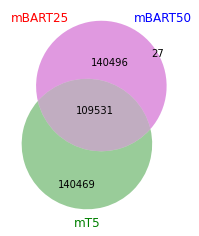
データセットはいずれも CommonCrawl で,mBART25とmBART50はトークナイザは言語コードの分が違うだけのようですね
ちなみに,異なる27個の語彙は以下の通りです.
‘af_ZA’,’az_AZ’,’bn_IN’,’fa_IR’,’gl_ES’,’he_IL’,’hr_HR’,’id_ID’,’ka_GE’,’km_KH’,’mk_MK’,’ml_IN’,’mn_MN’,’mr_IN’,’pl_PL’,’ps_AF’,’pt_XX’,’sl_SI’,’sv_SE’,’sw_KE’,’ta_IN’,’te_IN’,’th_TH’,’tl_XX’,’uk_UA’,’ur_PK’,’xh_ZA’
GPT-J vs GPT-2/3
これはGPT-JのGitHubに書いてありますが,GPT-2/3と同じtokenizer(Byte Pair Encoding)を使っているそうです.(以下略)
GPT2-japanese vs BERT-japanese vs T5-japanese
| モデル名 | トークン化手法 | データセット | リンク |
|---|---|---|---|
| GPT2-japanese | SentencePiece | Wikipedia(ja) | https://huggingface.co/rinna/japanese-gpt2-medium |
| BERT-japanese | WordPiece | IPA dictionary | https://huggingface.co/cl-tohoku/bert-base-japanese |
| T5-japanese | SentencePiece | Wikipedia(ja),OSCAR(ja),CC-100(ja) | https://huggingface.co/sonoisa/t5-base-japanese |
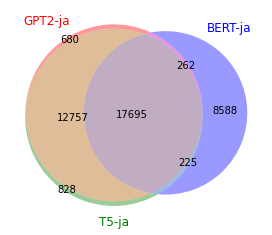
同じ日本語wikipediaをトークナイザの学習に使っているため,GPT2-japaneseとT5-japaneseの共通部分が大きいですね.微妙に異なる部分がるのは,special tokensやdumpの時期の違いによるものでしょうか.(何かご存知の方いらっしゃったらご教授ください)
最後に
モデルとトークナイザは学習が独立していることが多いため,トークナイザが単体でどのような挙動をしているかを知っておくことも重要なのだと思いました.この辺もちゃんと理解して「ニューラルネットの気持ち」になりたいですね.