(改)Real or Not? NLP with Disaster Tweets を解く
前回の記事を書いて以降、いくつか改善策を練った結果、精度が 74.539 % → 78.425 % に上がったため、その内容を書いておきます。
改善点
今回の改善点は主に4つ
- 人物系単語、地名系単語、@付き単語、リンクをまとめる
- 出現頻度の少ない単語は<unk>(辞書に存在しない単語)として扱う
- モデルをCNNに変更
- 学習時の<unk>含有率をテストデータに合わせる
trainデータを見てみると、@付き単語の種類数は2328に対して、@付き単語の出現回数は2759であり、ほとんどの出現回数は1回でした。もっとも使われている@付き単語は@YouTube(YouTube動画共有時についているやつ)で、82回でした。
今回、@付きアカウントは以下のように割り振りました。
1 | <youtube> : @YouTube |
リンクは<link>、地名は<location>、人物名は、出現頻度の多い政治家・歌手等を除いて、<person>にまとめました。
出現回数が1度のみの単語は、おそらくtestデータ中にも出現しにくいと考えられるため全て<unk>にまとめました。(<unk>は元々、テストデータの単語が学習データ中に存在しない時に変換する文字)
今回まとめた単語は以上ですが、これら以外にも、出現頻度が少ない単語を、ある一定のグループ名にまとめると、精度が上がるのではないかと思います。日が昇ってきたので前処理はこの辺で切り上げました
1.2.に関して、これら以外にも不要な記号等を削除した結果、25,000程度あった単語の種類が、6,000程度に減りました。
3.に関しては単純なCNNです。前回のモデルよりも、正解率が率が高くなりました。構造は以下のように、単純なものです。埋め込み次元は18次元としています。
1 | class CNN(nn.Module): |
4.に関しては、学習データ中のunk含有率:0.04140461215932914 テストデータ中のunk含有率:6.409214826048494 % この差分に近い、2.26%だけ<unk>をランダムで学習データに追加しました。
学習結果は以下の通りです。validationデータに対する正解率は0.77付近にいます。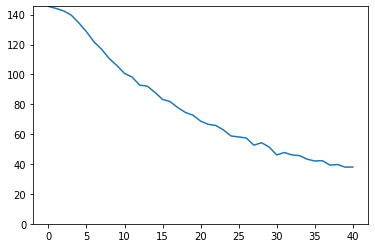
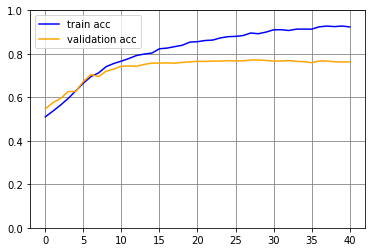
提出結果は以下の通りです。
おわりに
前回はデータをそのまま学習させていたため、今回はデータをいくつか前処理でまとめてみました。時間もかかって大変ですけど、データ数を減らすことで、結果的に学習時間を削減できましたので、もっと積極的にすべきですね..